Introduction to Heterogeneous Computing¶
You have already seen that you can decompose the task and distribute each smaller task to each worker, and let each node work simultaneously in an MPI program. Thus, it enables a programmer to work on a larger problem size, and reduce the computational time. Similarly, CUDA C is a GPU programming language, and provides another parallel programming model. Our goal of this module is to program in a hybrid environment, using CUDA and MPI.
It turns out that we can produce a new parallel programming model that combines MPI and CUDA together. The idea is that we use MPI to distribute work among nodes, each of which uses CUDA to work on its task. In order for this to work, we need to keep in mind that we need to have a cluster or something similar, where each node contains GPUs capable of doing CUDA computation. The Figure below illustrates the model for heterogeneous or hybrid programming.
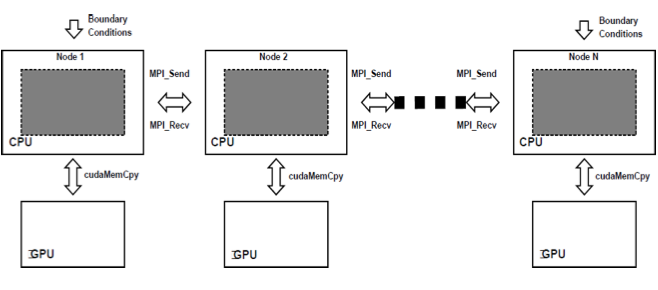
Figure 1: Heterogeneous Programming Model: CUDA and MPI from cacuda.googlecode.com [1]
Recommended Reading
References
| [1] | http://cacuda.googlecode.com/files/CaCUDA.pdf |
