Monte Carlo Estimate Pi¶
This example demonstrates the Monte Carlo method for estimating the value of
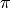 . Monte Carlo methods rely on repeated independent and random sampling.
Such methods work well with parallel and distributed systems as the work
can be split among many processes.
. Monte Carlo methods rely on repeated independent and random sampling.
Such methods work well with parallel and distributed systems as the work
can be split among many processes.
The problem can be imagined in terms of playing darts. Let the dartboard consist of a square target with a circular target inside of it. To solve this by means of using a ‘Monte Carlo Simulation’, you would simply throw a bunch of darts at the target and record the percentage that land in the inner circular target.
We can extend this idea to approximate quite easily.
Suppose the square target has a length of two feet and the circular target
has a radius of one foot.
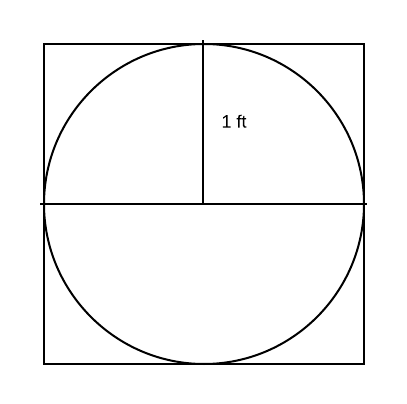
Based on the dimensions of the board, we have that the ratio of the area of the circle to the area of the square is
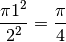
As it happens, we can calculate a value for the ratio of the area of the circle
to the area of the square with a Monte Carlo simulation. We pick random
points in the square and find the ratio of the number of points inside the circle
to the total number of points. This ratio should approach 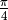 .
We multiply this by 4 to get our estimate of .
.
We multiply this by 4 to get our estimate of .
This can be simplified by using only a quarter of the board. The ratio of the
area of the circle to the area of the square is still /4. To
simulate the throw of a dart, we generate a number of random points with
coordinates (x,y). These coordinates are uniformly distributed random numbers
between 0 and 1. Then, we determine how many of these points fall inside of
the circle and take the ratio of the areas.
Code¶
file: MPI_examples/monteCarloPi/calcPiMPI/calcPiMPI.C
Build inside calcPiMPI directory:
make calcPiMPI
Execute on the command line inside calcPiMPI directory:
mpirun -np <N> ./calcPiMPI <number of tosses>
To do:
Find the speedup and efficiency of this program. To do so, you will need a sequential version of calculating pi using the Monte Carlo method. A sequential version of the code is located within the MPI_examples/monteCarloPi/calcPiSeq directory.
Use 2, 4, 8, 12, 14, and 16 for the number of processes and 16 million, 32 million, 64 million, 128 million, and 256 million for the number of tosses.
Record execution times from each combination in a table. Calculate the the speedup and efficiency of each combination and make corresponding speedup and efficiency graphs.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | /*
* Hannah Sonsalla, Macalester College, 2017
*
* calcPiMPI.C
*
* ...program uses MPI to calculate the value of Pi
*
* Usage: mpirun -np N ./calcPiMPI <number of tosses>
*
*/
#include <mpi.h>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void Get_input(int argc, char* argv[], int myRank, long* totalNumTosses_p);
long Toss (long numProcessTosses, int myRank);
int main(int argc, char** argv) {
int myRank, numProcs;
long totalNumTosses, numProcessTosses, processNumberInCircle, totalNumberInCircle;
double start, finish, loc_elapsed, elapsed, piEstimate;
double PI25DT = 3.141592653589793238462643; /* 25-digit-PI*/
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numProcs);
MPI_Comm_rank(MPI_COMM_WORLD, &myRank);
Get_input(argc, argv, myRank, &totalNumTosses); // Read total number of tosses from command line
numProcessTosses = totalNumTosses/numProcs;
MPI_Barrier(MPI_COMM_WORLD);
start = MPI_Wtime();
processNumberInCircle = Toss(numProcessTosses, myRank);
finish = MPI_Wtime();
loc_elapsed = finish-start;
MPI_Reduce(&loc_elapsed, &elapsed, 1, MPI_DOUBLE, MPI_MAX, 0, MPI_COMM_WORLD);
MPI_Reduce(&processNumberInCircle, &totalNumberInCircle, 1, MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);
if (myRank == 0) {
piEstimate = (4*totalNumberInCircle)/((double) totalNumTosses);
printf("Elapsed time = %f seconds \n", elapsed);
printf("Pi is approximately %.16f, Error is %.16f\n", piEstimate, fabs(piEstimate - PI25DT));
}
MPI_Finalize();
return 0;
}
/* Function gets input from command line for totalNumTosses */
void Get_input(int argc, char* argv[], int myRank, long* totalNumTosses_p){
if (myRank == 0) {
if (argc!= 2){
fprintf(stderr, "usage: mpirun -np <N> %s <number of tosses> \n", argv[0]);
fflush(stderr);
*totalNumTosses_p = 0;
} else {
*totalNumTosses_p = atoi(argv[1]);
}
}
// Broadcasts value of totalNumTosses to each process
MPI_Bcast(totalNumTosses_p, 1, MPI_LONG, 0, MPI_COMM_WORLD);
// 0 totalNumTosses ends the program
if (*totalNumTosses_p == 0) {
MPI_Finalize();
exit(-1);
}
}
/* Function implements Monte Carlo version of tossing darts at a board */
long Toss (long processTosses, int myRank){
long toss, numberInCircle = 0;
double x,y;
unsigned int seed = (unsigned) time(NULL);
srand(seed + myRank);
for (toss = 0; toss < processTosses; toss++) {
x = rand_r(&seed)/(double)RAND_MAX;
y = rand_r(&seed)/(double)RAND_MAX;
if((x*x+y*y) <= 1.0 ) numberInCircle++;
}
return numberInCircle;
}
|
MPI Basics¶
- mpirun: On the command line, mpirun tells the system to start <N> instances of the program.
- MPI_Init: The call to MPI_Init on tells the MPI system to setup. This includes allocating storage for message buffers and deciding the rank each process receives. MPI_Init also defines a communicator called MPI_COMM_WORLD.
- MPI_COMM_WORLD: MPI_COMM_WORLD is the communicator in MPI. A communicator is a group of processes that can communicate with each other by sending messages. MPI_COMM_WORLD has two main functions. The function MPI_Comm_rank returns in its second argument the rank of the calling process in the communicator. Similarly, the function MPI_Comm_size returns as its second argument the number of processes in MPI_COMM_WORLD.
- MPI_Finalize: The MPI_Finalize command tells the MPI system that we are finished and it deallocates MPI resources.
User Input¶
The Get_input function on line 55 shows how to incorporate user input from the command line. Note that only one process (master) takes part in getting the input. The master process prints a usage message if the number of arguments is not equal to two. This means that the user has not included the correct amount of arguments. Otherwise, totalNumTosses variable is set to point to argument two. In order to send the data from the master to all of the processes in the communicator, it is necessary to broadcast. During a broadcast, one process sends the same data to all of the processes.
/* Function gets input from command line for totalNumTosses */
void Get_input(int argc, char* argv[], int myRank, long* totalNumTosses_p){
if (myRank == 0) {
if (argc!= 2){
fprintf(stderr, "usage: mpirun -np <N> %s <number of tosses> \n", argv[0]);
fflush(stderr);
*totalNumTosses_p = 0;
} else {
*totalNumTosses_p = atoi(argv[1]);
}
}
// Broadcasts value of totalNumTosses to each process
MPI_Bcast(totalNumTosses_p, 1, MPI_LONG, 0, MPI_COMM_WORLD);
// 0 totalNumTosses ends the program
if (*totalNumTosses_p == 0) {
MPI_Finalize();
exit(-1);
}
Timing¶
Timing can aid in performance evaluation of MPI programs. For this example, lines 36 through 41 correspond to the timing of the main function (the actual tosses). MPI provides the MPI_Wtime function which returns the time in seconds since some time in the past. Note MPI_Wtime returns wall clock time.
A barrier is used before the start of timing (line 36) so that all of the processes are reasonably close to starting at the same instant. When timing, we want a single time - the time that elapsed when the last process finished. To do so, MPI_Reduce is called on line 41 using the MPI_MAX operator. Thus, the largest process time in the loc_elapsed variable will be stored in the elapsed variable.
MPI_Barrier(MPI_COMM_WORLD);
start = MPI_Wtime();
processNumberInCircle = Toss(numProcessTosses, myRank);
finish = MPI_Wtime();
loc_elapsed = finish-start;
MPI_Reduce(&loc_elapsed, &elapsed, 1, MPI_DOUBLE, MPI_MAX, 0, MPI_COMM_WORLD);
MPI Reduce¶
In this example, each process takes part in randomly picking a certain number
of random points (tosses) and determining how many of them fall inside of the
circle. We need to be able to sum all of the points that land inside of the circle
in order to estimate . In other words, we need to reduce the individual
computations from each process into one value. MPI provides the reduce function
for this purpose which is considered collective communication. MPI, has
built-in computations including MPI_MAX, MPI_SUM, MPI_PROD, etc. Below is the
line of code in which we reduce the number of points that landed in the circle
in each process to a single value representing the total number of points that
landed in the circle.
MPI_Reduce(&processNumberInCircle, &totalNumberInCircle, 1, MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);
