Other ways to split the work¶
We have referred to the section of the array that a processing unit works on as a chunk of the array assigned to each processing unit. The example we have presented here divides the original and result arrays into equal-sized contiguous chunks, where the size of each chunk is the number of elements divided by the number of processing units (n/p). As you can imagine, there are other ways that the work could be divided. In fact, in the case of the CUDA example, each GPU thread worked on one element (the thread block was analogous to our processing unit). Chunks of size one are one possible alternative: every processing unit could work on elements like this:
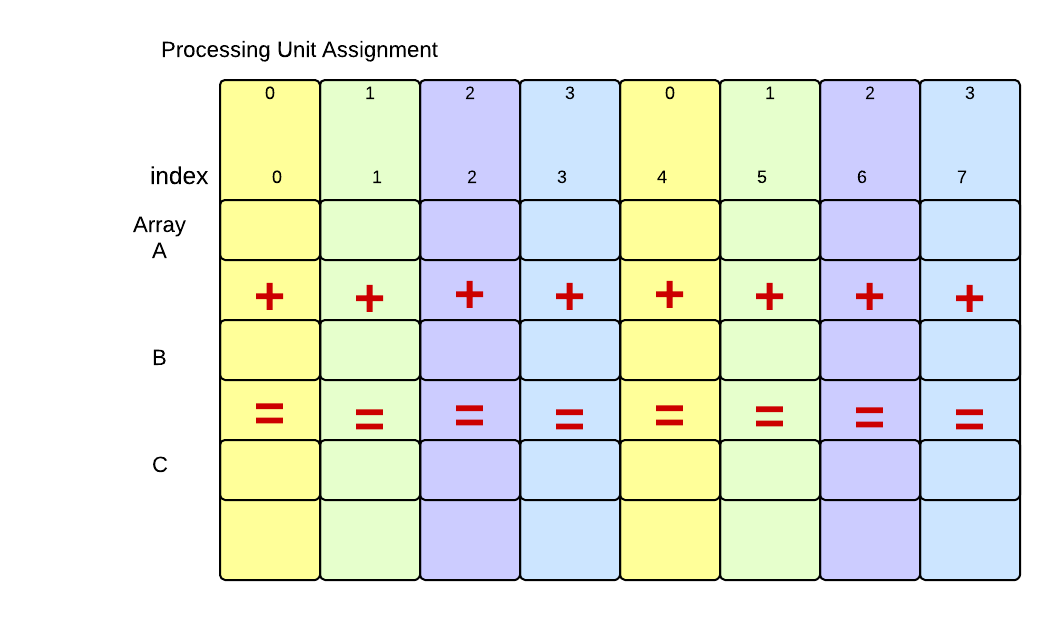
This type of decomposition might work fairly well for shared-memory multicore computers using OpenMP, but it doesn’t make as much sense for distributed systems using MPI, where the data must be sent from the master process to the other processes in the cluster– it is much easier to send a consecutive chuank at one time that small lieces over and over again.
Another alternative is to choose a chunk size smaller than n/p and each processing unit will work on then next available chunk. You can explore these alternatives in OpenMP by looking at documentation for the schedule clause of the pragmaa ‘omp parallel for’. The CUDA code example called VectorAdd/CUDA/VA-GPU-larger.cu explores this concept.
Questions for reflection¶
In what situations would MPI on a cluster of computers be advantageous for problems requiring data decomposition?
In what situations would CUDA on a GPU be advantageous for problems requiring data decomposition?
In what situations would OpenMP on a multicore computer be advantageous for problems requiring data decomposition?
In multicore machines, the operating system ultimately schedules threads to run. Look up what default scheduling of threads to chunks is used in OpenMP if we leave out the schedule clause of the pragmaa ‘omp parallel for’. Can you find any information or think of why this decomposition is the default?
